
Ready to start AI? Maybe you have started practical learning in the field of machine learning, but still want to expand your knowledge and further understand the topics you have heard but have no time to understand.
These machine learning terminology provides a brief introduction to the most important machine learning concepts—including topics of interest to both business and technology. Before you meet an AI instructor, this is a content that is not exhaustive, but is easy to understand and easy to navigate at work and before the interview.
1 natural language processing
Natural language processing is a common concept for many machine learning methods, which makes it possible for a computer to understand and perform operations using the language that people read or write.
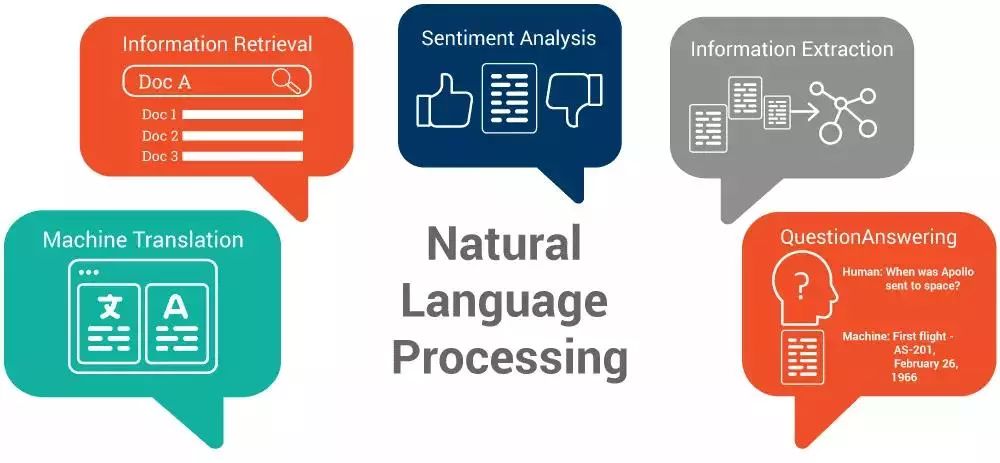
The most important and useful examples of natural language processing:
1 Text Classification and Sorting The goal of this task is to predict a label (category) for a text or to sort the associated text in a list. It can be used to filter spam (predicting whether an email is spam) or to categorize text content (screening out articles related to your competitors from the web).
2 Sentiment Analysis Sentence analysis is to determine a person's perception or emotional response to a topic, such as positive or negative emotions, anger, irony, etc. It is widely used in user satisfaction surveys (such as analysis of product reviews).
3 Document Summary File Summary is a short and meaningful description of long text (such as documents, research papers). Interested in the direction of natural language processing?
4 Named Entity Recognition The Named Entity Recognition algorithm is used to process a series of messy texts and identify target (entity) predefined categories such as person, company name, date, price, title, and more. It can convert messy text information into a regular class table format for fast analysis of text.
5 Speech recognition Speech recognition technology is used to obtain a textual representation of a speech signal spoken by a person. You may have heard of Siri's assistant? This is one of the best examples of speech recognition applications.
6 The understanding of natural language and the understanding of generating natural language is the conversion of human-generated text into a more formal expression through a computer. In turn, natural language generation techniques convert some formal and logical expressions into human-like generated text. Today, natural language understanding and generation is primarily used for the automatic generation of chat bots and reports.
Conceptually, it is the opposite of the entity naming recognition task.
7 Machine Translation Machine translation is the task of automatically translating a piece of text or speech from one language to another.
2 database
Database is a necessary part of machine learning. If you want to build a machine learning system, you can either get the data from public resources or collect the data yourself. All data sets used to build and test machine learning models become databases. Basically, data scientists divide the data into three parts:
Training data: Training data is used to train the model. This means that the machine learning model needs to recognize and learn the patterns of the data and determine the most important data characteristics in the prediction process.
Validation data: Validation data is used to fine tune model parameters and compare different models to determine the optimal model. The verification data should be different from the training data and cannot be used in the training phase. Otherwise, the model will be over-fitting and the generalization of new data will be poor.
Test data: This may seem a bit monotonous, but this is usually the third and final test set (often also called confrontation data). Once the final model is determined, it is used to test the performance of the model on data sets that have never been seen before, such as when the data was never used in building a model or determining a model.

Image: Visualization of the MNIST database obtained by mixing the t-SNE and Jonker-Volgenant algorithms. T-SNE is a widely used dimensionality reduction algorithm that can be better visualized and further processed by compressing the expression of data.
3 Computer Vision
Computer Vision is an area of ​​artificial intelligence that focuses on analyzing and deeply understanding image and video data. The most common problems in the field of computer vision include:
1 Image Classification Image classification is a computer vision task that teaches a model to identify a given image. For example, training a model to identify multiple objects in a common scene (this can be applied to autonomous driving).
2 Target Detection Target detection is a computer vision task that teaches a model to detect an instance of a category from a series of predefined categories and to draw it out in a rectangular box. For example, target detection is used to construct a face recognition system. The model can detect each face in the picture and draw the corresponding rectangular frame (by the way, the image classification system can only recognize whether there is a face in a picture, but can not detect the position of the face, and the target detection The system can be).

3 Image Segmentation Image segmentation is a computer vision task in which the training model de-labels each pixel value of a class and can roughly determine the predefined categories to which a given pixel belongs.

Significant detection
Significant detection is a computer vision task in which the training model produces the most significant areas. This can be used to determine the location of the billboard in the video.
4 Supervised learning
Supervised learning is a collection of machine learning models that use examples to teach model learning. This means that the data used to supervise the learning task needs to be labeled (specifying the correct, real category). For example, if we want to build a machine learning model to identify whether a given text has been tagged, we need to provide the model with a tagged sample set (text + information, whether the text has been tagged). Given a new, unseen example, the model can predict its goals, for example, specifying the label of the sample, 1 for the marked and 0 for the unlabeled.
5 Unsupervised learning
Compared to supervised learning, unsupervised learning models are self-learning through observation. The data used by the algorithm is unmarked (ie, the data provided to the algorithm is no real tag value). An unsupervised learning model can discover the correlation between different inputs. The most important unsupervised learning technique is the clustering method. For a given data, the model can get different clusters of inputs (for similar data aggregates in the same class) and can classify new, unseen inputs into similar clusters.

6 Reinforcement learning
Reinforcement learning differs from those previously mentioned. Reinforce learning algorithm A "game" process whose goal is to maximize "game rewards." The algorithm tries to determine different "walking methods" through repeated experiments and see which way can maximize "game gains"
The most well-known example of reinforcement learning is to teach computers to solve Rubik's cube problems or to play chess, but the problem that reinforcement learning can solve is not only games. Recently, reinforcement learning has been heavily applied to real-time bidding, and its model is responsible for auctioning prices for an ad and its reward is the user's conversion rate.
Want to learn the application of artificial intelligence in real-time bidding and programmatic advertising?
Neural networks are a very broad collection of machine learning models. Its main idea is to simulate the behavior of the human brain to process data. Just like the network formed by the interconnection of real neurons in the brain, the artificial neural network consists of multiple layers. Each layer is a collection of neurons that are responsible for detecting different foods. A neural network can process data continuously, which means that only the first layer is directly connected to the input. As the number of model layers increases, the model will learn more and more complex data structures. When the number of layers increases, the model is usually a so-called deep learning model. It is difficult to determine a specific network layer for a deep network. Usually, a 3-layer neural network is as deep as 10 years ago, but today it usually requires 20 layers.
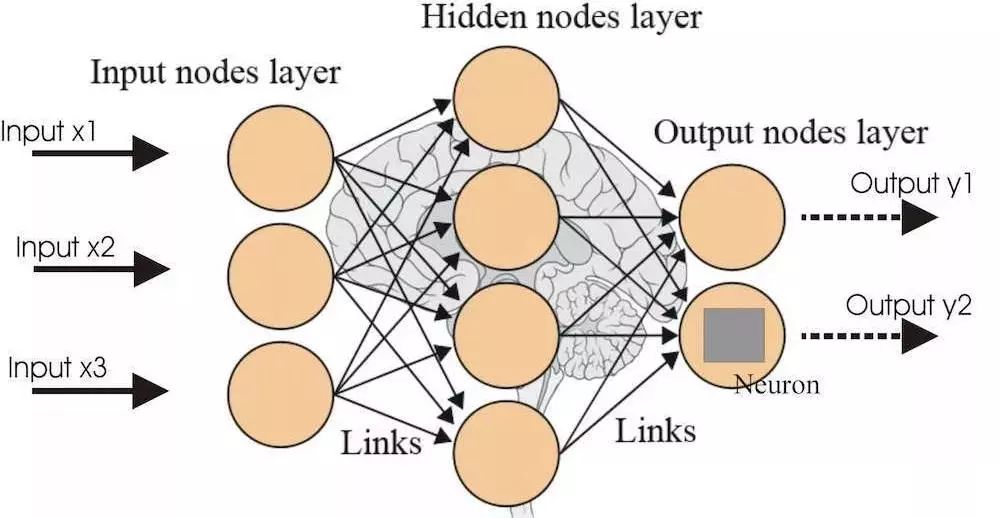
There are many different variants of neural networks, the most common ones are:
• Convolutional neural networks—which have made a huge breakthrough in computer vision tasks (and today, it also helps solve natural language processing problems).
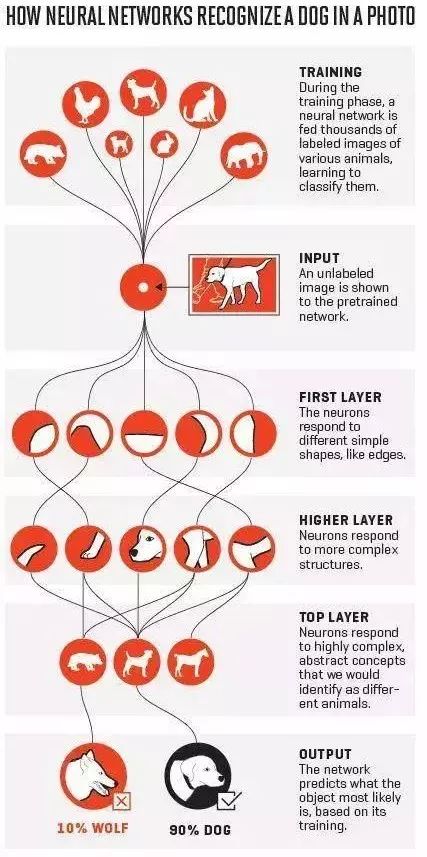
• Recurrent neural networks—designed to process data with sequence characteristics, such as text or stock fares. This is a relatively old neural network, but with the rapid advancement of modern computer computing power over the past 20 years, its training has become easier and has been applied in many cases.
• Fully connected neural network—this is the simplest model for working with static/tabular data.
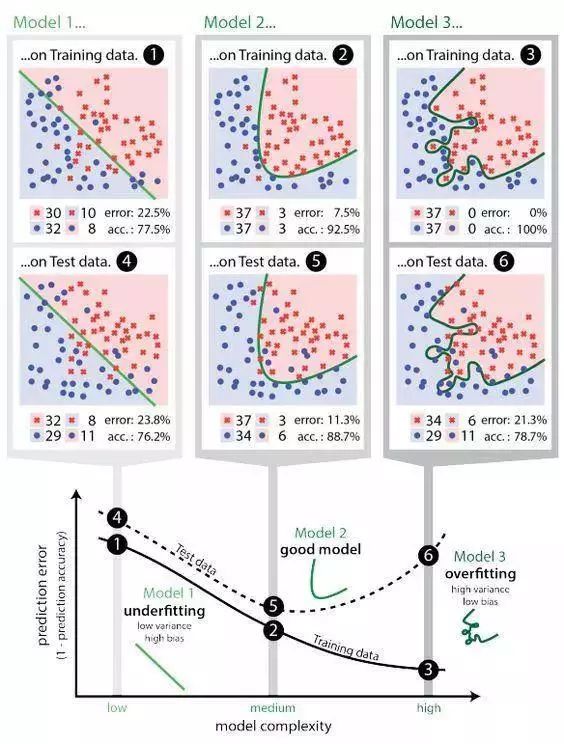
8 overfitting
When the model learns from insufficient data, there will be deviations, which will have a negative impact on the model. This is a very common and important issue.
When you enter a bakery at different times, and every time the rest of the cake is not what you like, then you may be disappointed with this bakery, even if there are many other customers who may be satisfied with the rest of the cake. If you are a machine learning model, you can say that you have over-fitting this small number of samples—to build a model with an offset, the resulting representation does not over-fitting the real data.
When overfitting occurs, it usually means that the model treats random noise as data and fits it as an important signal, which is why the model's performance on new data is degraded (noise is also different). This is very common on some very complex models such as neural networks or accelerated gradient models.
Imagine building a model to detect specific sports related to the Olympics that appear in the article. Since the training set used is biased from the article, the model may learn the characteristics of words such as "Olympics" and cannot detect articles that do not contain the word.
This DC Source System output current is up to 324A max by connecting the internal single unit rack mount DC Power Supply in parallel. Output voltage is up to 750VDC max (recommend not to exceed 800V) by connecting the internal single unit in series.
Some features of these adjustable dc power supply as below:
- With accurate voltage and current measurement capability.
- Coded Knob, multifunctional keyboard.
- Standard RS232/RS485/USB/LAN communication interfaces, GPIB is optional.
- Remote sensing line voltage drop compensation.
- Equips with LIST waveform editing function.
- Use the Standard Commands for Programmable Instrumentation(SCPI) communication protocol.
- Have obtained CE certification.
75V DC Source System,AC DC Electronics Power Supply,Dc Power System,Stable Dc Voltage Source
APM Technologies Ltd , https://www.apmpowersupply.com